目录
背景
为什么使用消息队列
消息队列
问题一:为什么使用消息队列
- 解耦
- 异步
- 削峰
问题2:使用了消息队列会有什么缺点?
- 系统可用性降低、系统复杂性增加;
- 系统可用性降低:是指你的系统加一个消息中间件,那消息队列挂了,你的系统将会受到严重的影响,甚至导致整个系统无法正常的提供服务;
- 系统的复杂性增加:是指引入了消息中间件,必须考虑数据的一致性问题、消息的重复消费,消息的可靠传输(传输的过程中不丢失)等一系列问题,
- 所以要结合自己的业务场景去引入相关的技术,脱离业务的架构都是耍牛氓。
kafka
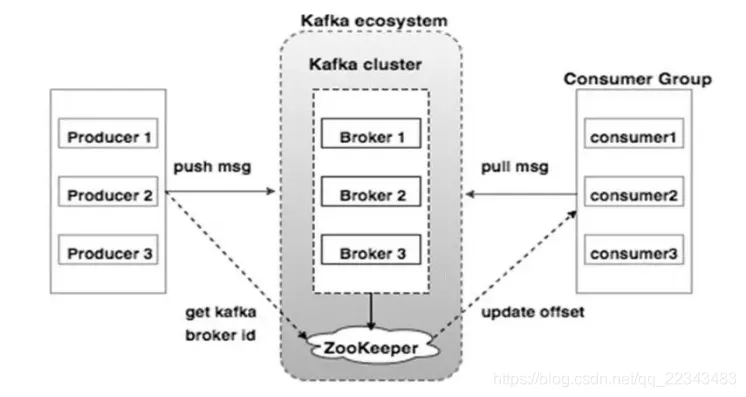
Kafka 可能出现的情况
1、生产者丢数据
在kafka生产中,基本都有一个leader和多个follwer。follwer会去同步leader的信息。 因此,为了避免生产者丢数据,做如下两点配置:
- 第一个配置要在producer端设置acks=all。这个配置保证了,follwer同步完成后,才认为消息发送成功。
- 在producer端设置retries=MAX,一旦写入失败,这无限重试
2、消息队列丢数据
针对消息队列丢数据的情况,无外乎就是,数据还没同步,leader就挂了,这时zookpeer会将其他的follwer切换为leader,那数据就丢失了。
-
针对这种情况,应该做两个配置。
- replication.factor参数,这个值必须大于1,即要求每个partition必须有至少2个副本
- min.insync.replicas参数,这个值必须大于1,这个是要求一个leader感知到有至少一个follower还跟自己保持联系
-
这两个配置加上上面生产者的配置联合起来用,基本可确保kafka不丢数据。
3、消费者丢数据
这种情况一般是自动提交了offset,然后你处理程序过程中挂了。kafka以为你处理好了。
-
offset:指的是kafka的topic中的每个消费组消费的下标。
-
简单的来说就是一条消息对应一个offset下标,每次消费数据的时候如果提交offset,那么下次消费就会从提交的offset加一那里开始消费。
-
比如一个topic中有100条数据,我消费了50条并且提交了,那么此时的kafka服务端记录提交的offset就是49(offset从0开始),那么下次消费的时候offset就从50开始消费。
-
-
解决方案也很简单,改成手动提交offset即可。
kafka为什么快
- 磁盘顺序写
- 零拷贝
- Page Cache
总结
本文作者:曹子昂
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录